AutoGenBench is a standalone tool for evaluating AutoGen agents and
workflows on common benchmarks.
TL;DR
Today we are releasing AutoGenBench - a tool for evaluating AutoGen agents and workflows on established LLM and agentic benchmarks.
AutoGenBench is a standalone command line tool, installable from PyPI, which handles downloading, configuring, running, and reporting supported benchmarks. AutoGenBench works best when run alongside Docker, since it uses Docker to isolate tests from one another.
- See the AutoGenBench README for information on installation and running benchmarks.
- See the AutoGenBench CONTRIBUTING guide for information on developing or contributing benchmark datasets.
Quick Start
Get started quickly by running the following commands in a bash terminal.
Note: You may need to adjust the path to the OAI_CONFIG_LIST, as appropriate.
export OAI_CONFIG_LIST=$(cat ./OAI_CONFIG_LIST)
pip install autogenbench
autogenbench clone HumanEval
cd HumanEval
cat README.md
autogenbench run --subsample 0.1 --repeat 3 Tasks/human_eval_two_agents.jsonl
autogenbench tabulate Results/human_eval_two_agents
Introduction
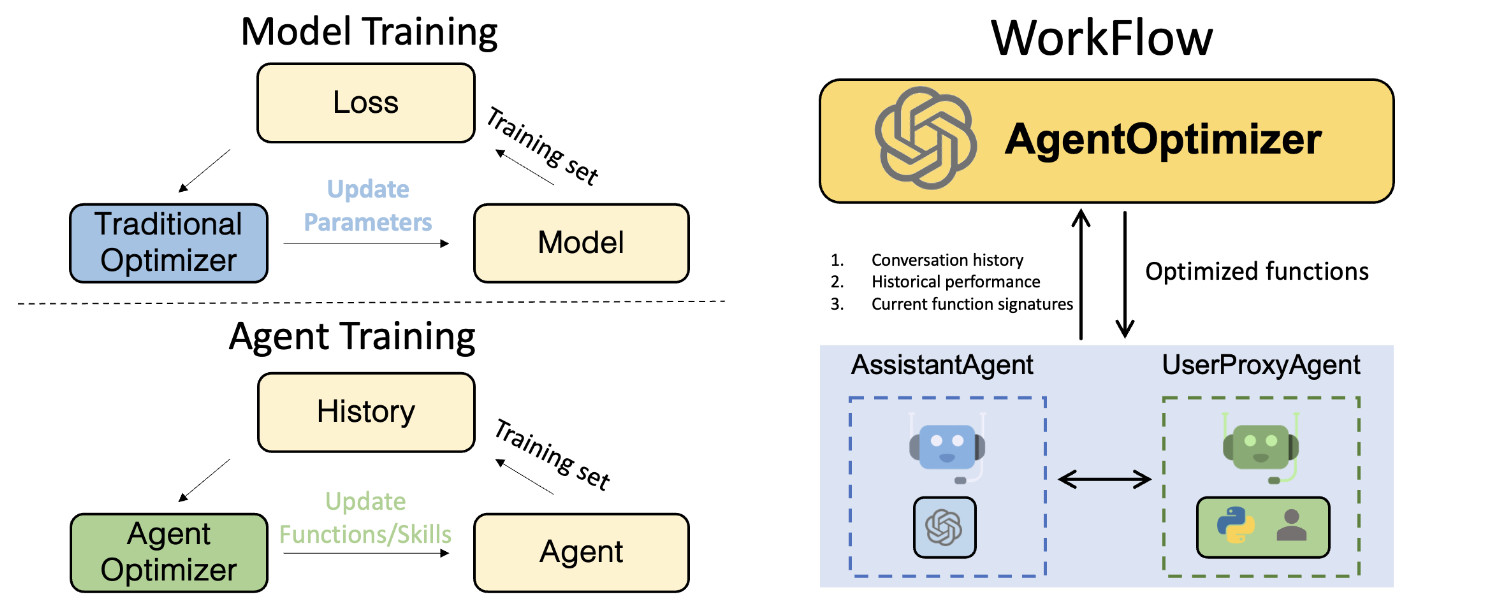
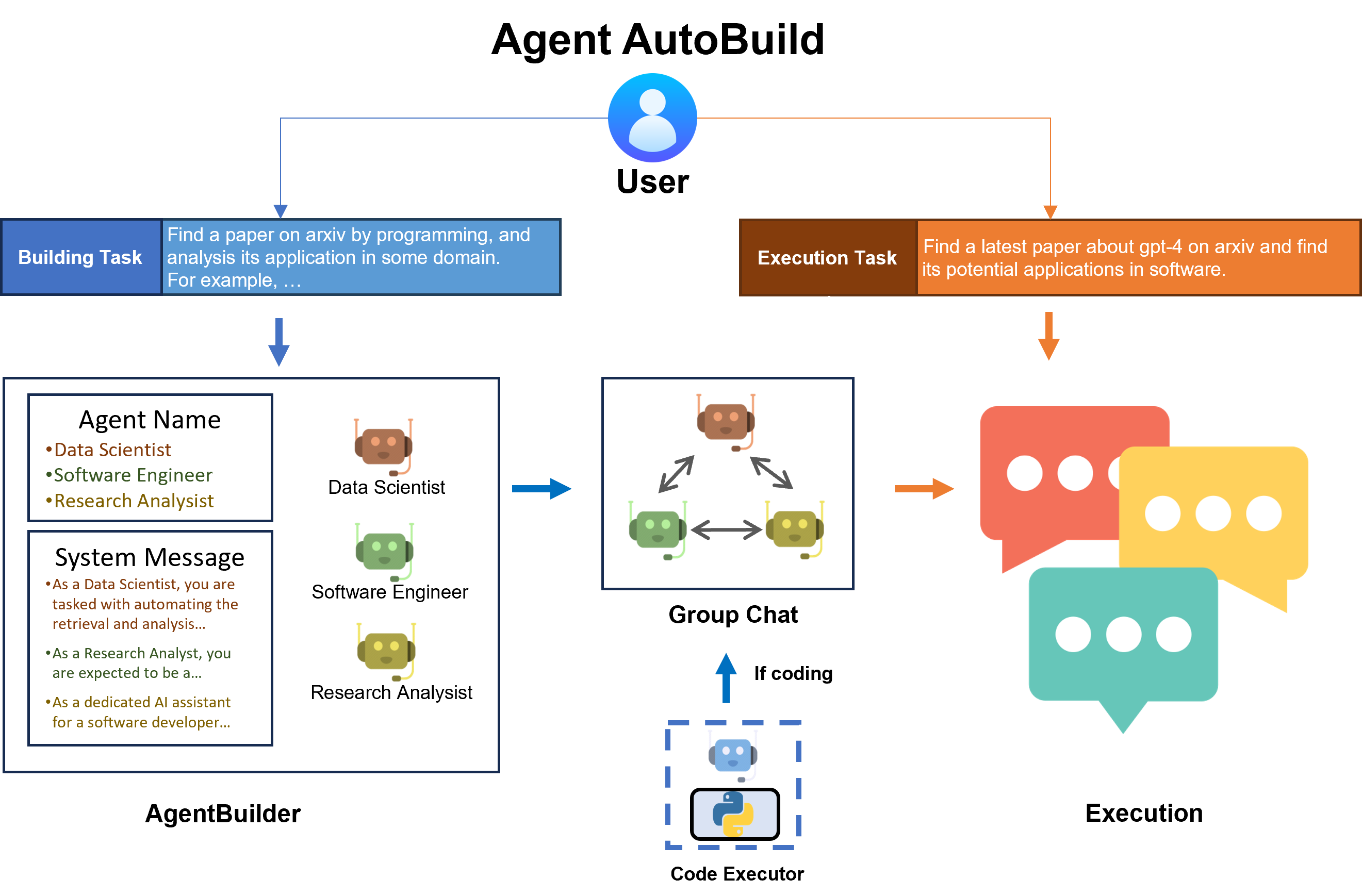
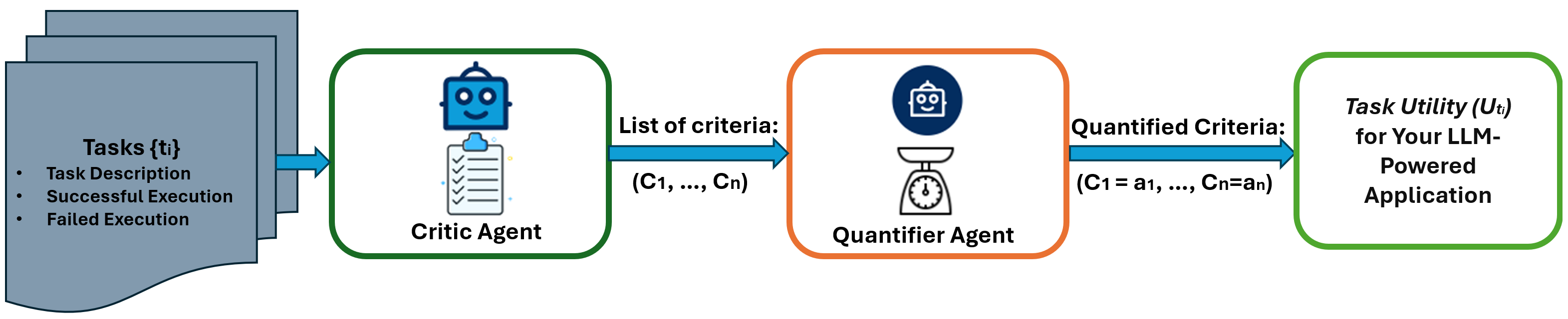
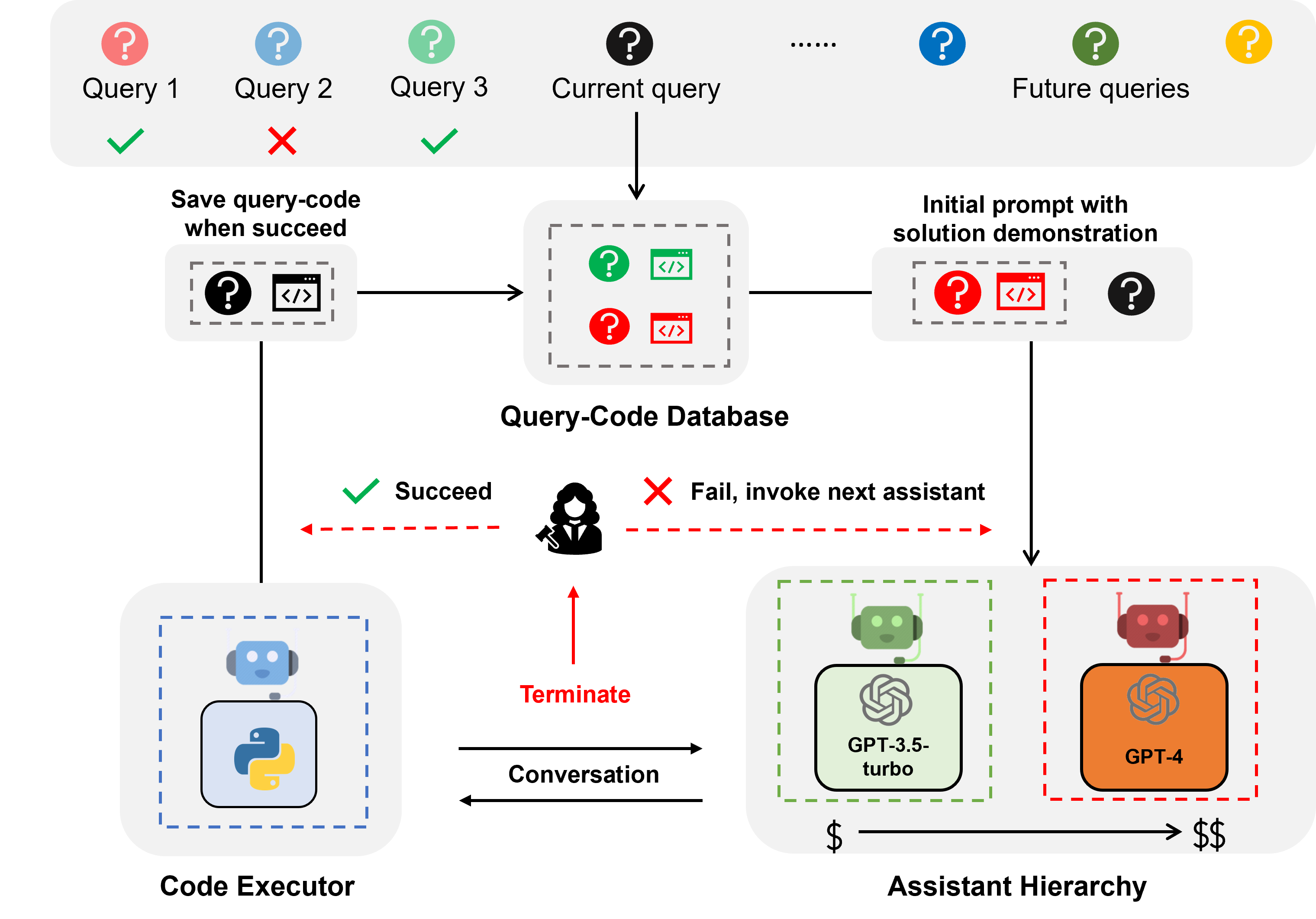
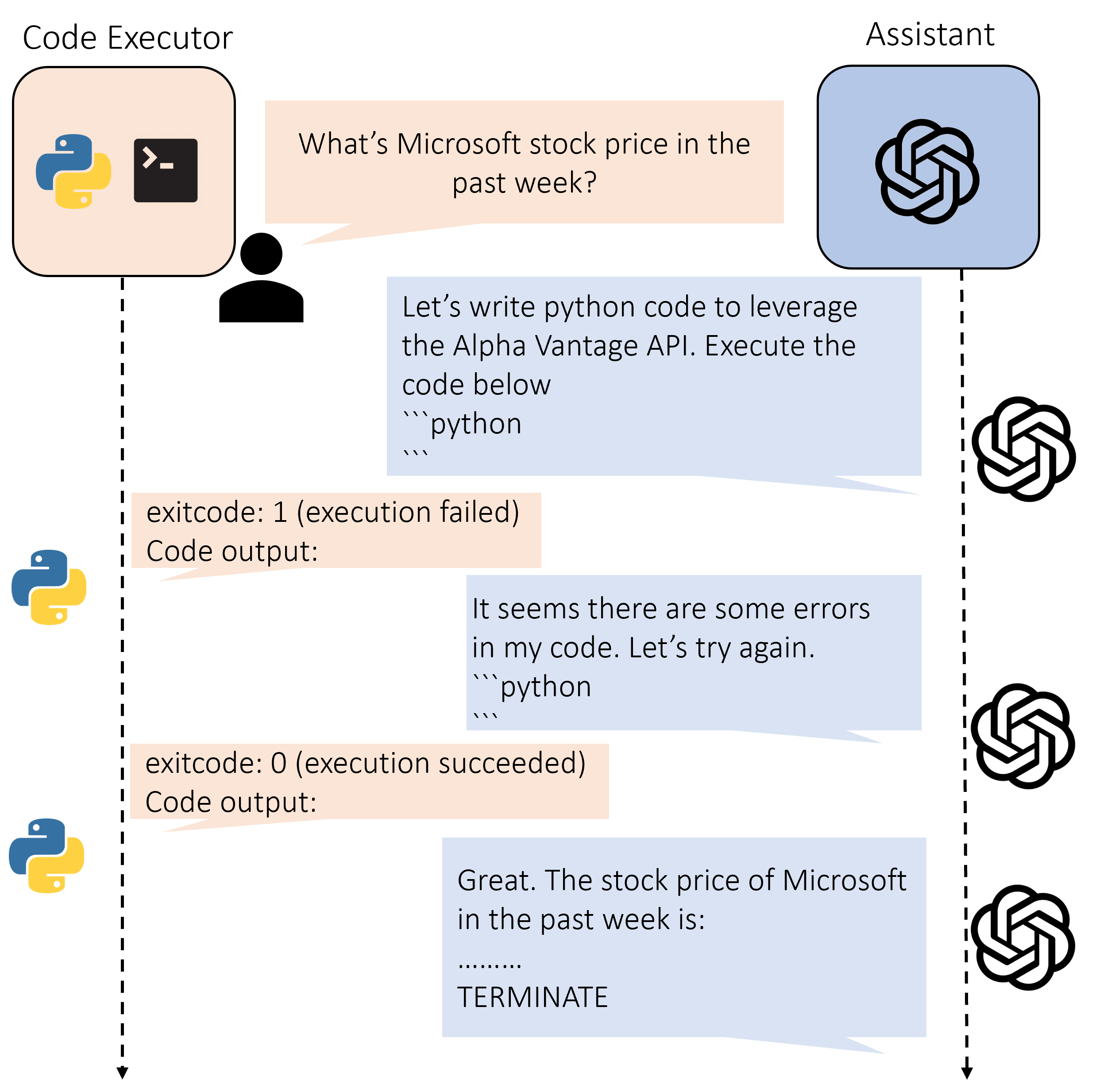
Measurement and evaluation are core components of every major AI or ML research project. The same is true for AutoGen. To this end, today we are releasing AutoGenBench, a standalone command line tool that we have been using to guide development of AutoGen. Conveniently, AutoGenBench handles: downloading, configuring, running, and reporting results of agents on various public benchmark datasets. In addition to reporting top-line numbers, each AutoGenBench run produces a comprehensive set of logs and telemetry that can be used for debugging, profiling, computing custom metrics, and as input to AgentEval. In the remainder of this blog post, we outline core design principles for AutoGenBench (key to understanding its operation); present a guide to installing and running AutoGenBench; outline a roadmap for evaluation; and conclude with an open call for contributions.
Design Principles
AutoGenBench is designed around three core design principles. Knowing these principles will help you understand the tool, its operation and its output. These three principles are:
-
Repetition: LLMs are stochastic, and in many cases, so too is the code they write to solve problems. For example, a Python script might call an external search engine, and the results may vary run-to-run. This can lead to variance in agent performance. Repetition is key to measuring and understanding this variance. To this end, AutoGenBench is built from the ground up with an understanding that tasks may be run multiple times, and that variance is a metric we often want to measure.
-
Isolation: Agents interact with their worlds in both subtle and overt ways. For example an agent may install a python library or write a file to disk. This can lead to ordering effects that can impact future measurements. Consider, for example, comparing two agents on a common benchmark. One agent may appear more efficient than the other simply because it ran second, and benefitted from the hard work the first agent did in installing and debugging necessary Python libraries. To address this, AutoGenBench isolates each task in its own Docker container. This ensures that all runs start with the same initial conditions. (Docker is also a much safer way to run agent-produced code, in general.)
-
Instrumentation: While top-line metrics are great for comparing agents or models, we often want much more information about how the agents are performing, where they are getting stuck, and how they can be improved. We may also later think of new research questions that require computing a different set of metrics. To this end, AutoGenBench is designed to log everything, and to compute metrics from those logs. This ensures that one can always go back to the logs to answer questions about what happened, run profiling software, or feed the logs into tools like AgentEval.
Installing and Running AutoGenBench
As noted above, isolation is a key design principle, and so AutoGenBench must be run in an environment where Docker is available (desktop or Engine). It will not run in GitHub codespaces, unless you opt for native execution (which is strongly discouraged). To install Docker Desktop see https://www.docker.com/products/docker-desktop/.
Once Docker is installed, AutoGenBench can then be installed as a standalone tool from PyPI. With pip, installation can be achieved as follows:
pip install autogenbench
After installation, you must configure your API keys. As with other AutoGen applications, AutoGenBench will look for the OpenAI keys in the OAI_CONFIG_LIST file in the current working directory, or the OAI_CONFIG_LIST environment variable. This behavior can be overridden using a command-line parameter.
If you will be running multiple benchmarks, it is often most convenient to leverage the environment variable option. You can load your keys into the environment variable by executing:
export OAI_CONFIG_LIST=$(cat ./OAI_CONFIG_LIST)
A Typical Session
Once AutoGenBench and necessary keys are installed, a typical session will look as follows:
autogenbench clone HumanEval
cd HumanEval
cat README.md
autogenbench run --subsample 0.1 --repeat 3 Tasks/human_eval_two_agents.jsonl
autogenbench tabulate results/human_eval_two_agents
Where:
autogenbench clone HumanEvaldownloads and expands the HumanEval benchmark scenario.cd HumanEval; cat README.mdnavigates to the benchmark directory, and prints the README (which you should always read!)autogenbench run --subsample 0.1 --repeat 3 Tasks/human_eval_two_agents.jsonlruns a 10% subsample of the tasks defined inTasks/human_eval_two_agents.jsonl. Each task is run 3 times.autogenbench tabulate results/human_eval_two_agentstabulates the results of the run.
After running the above tabulate command, you should see output similar to the following:
Trial 0 Trial 1 Trial 2
Task Id Success Success Success
------------- --------- --------- ---------
HumanEval_107 False True True
HumanEval_22 True True True
HumanEval_43 True True True
HumanEval_88 True True True
HumanEval_14 True True True
HumanEval_157 True True True
HumanEval_141 True True True
HumanEval_57 True True True
HumanEval_154 True True True
HumanEval_153 True True True
HumanEval_93 False True False
HumanEval_137 True True True
HumanEval_143 True True True
HumanEval_13 True True True
HumanEval_49 True True True
HumanEval_95 True True True
------------- --------- --------- ---------
Successes 14 16 15
Failures 2 0 1
Missing 0 0 0
Total 16 16 16
CAUTION: 'autogenbench tabulate' is in early preview.
Please do not cite these values in academic work without first inspecting and verifying the results in the logs yourself.
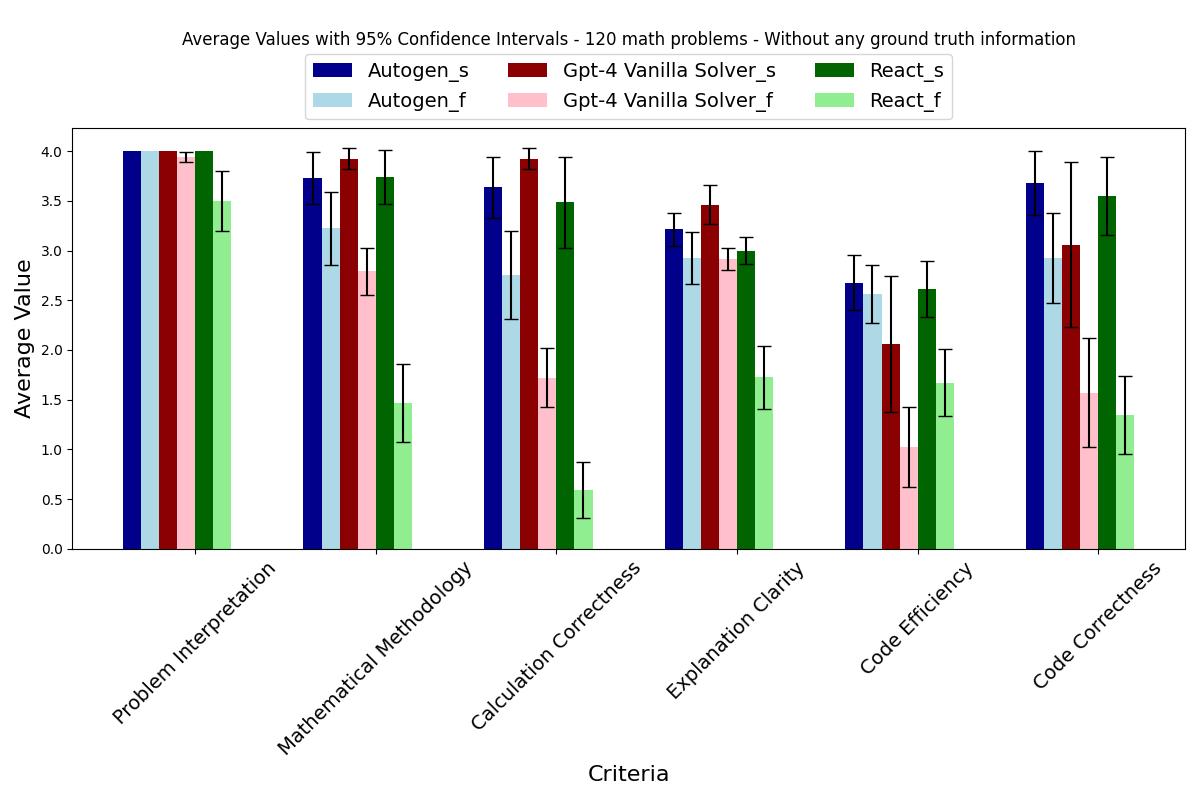
From this output we can see the results of the three separate repetitions of each task, and final summary statistics of each run. In this case, the results were generated via GPT-4 (as defined in the OAI_CONFIG_LIST that was provided), and used the TwoAgents template. It is important to remember that AutoGenBench evaluates specific end-to-end configurations of agents (as opposed to evaluating a model or cognitive framework more generally).
Finally, complete execution traces and logs can be found in the Results folder. See the AutoGenBench README for more details about command-line options and output formats. Each of these commands also offers extensive in-line help via:
autogenbench --helpautogenbench clone --helpautogenbench run --helpautogenbench tabulate --help
Roadmap
While we are announcing AutoGenBench, we note that it is very much an evolving project in its own right. Over the next few weeks and months we hope to:
- Onboard many additional benchmarks beyond those shipping today
- Greatly improve logging and telemetry
- Introduce new core metrics including total costs, task completion time, conversation turns, etc.
- Provide tighter integration with AgentEval and AutoGen Studio
For an up to date tracking of our work items on this project, please see AutoGenBench Work Items
Call for Participation
Finally, we want to end this blog post with an open call for contributions. AutoGenBench is still nascent, and has much opportunity for improvement. New benchmarks are constantly being published, and will need to be added. Everyone may have their own distinct set of metrics that they care most about optimizing, and these metrics should be onboarded. To this end, we welcome any and all contributions to this corner of the AutoGen project. If contributing is something that interests you, please see the contributor’s guide and join our Discord discussion in the #autogenbench channel!